Overview
Divooka is a cutting-edge visual programming platform developed by Methodox Technologies, Inc. It enables users to build and deploy complex applications through a drag-and-drop, node-based interface that integrates seamlessly with C# libraries.
Key Features
- General-Purpose & Flexible: Suitable for a wide range of use cases – from business tools to innovative software products – supporting both automation and application development.
- Node-Based Visual Interface: Workflows are constructed visually by connecting nodes that represent data operations, logic, APIs, and more.
- Multiple Distributions:
- Divooka Explore: A beginner-friendly, Windows-only edition designed for learning, data analytics, dashboards, programming, and everyday utilities.
- Divooka Compute: A professional package built on the same engine, aimed at power users.
- Cross-Platform Support: While early versions support Windows, full Linux and macOS support is planned.
- Strong Architectural Foundations: Based on Data-Driven Design principles, Divooka emphasizes modular, external control of behavior through data files – streamlining workflows without modifying code.
- Active Development & Community: Ongoing updates, documentation (wiki), tutorials, a Discord community, and blog posts ensure an active ecosystem.
Divooka is built around node graphs as executable documents. Instead of writing sequential code, developers construct graphs of nodes, where each node represents a unit of computation or data. This graph-based approach supports both dataflow-oriented and procedural-oriented paradigms.
A Divooka script file (a “Divooka Document”) acts as a container for node graphs.
At its simplest:
- A Divooka document contains multiple graphs.
- Each graph contains multiple nodes.
- Nodes have a type, an optional ID, and attributes.
- Node attributes can connect to other nodes’ attributes.
In a Dataflow Context, node connections are acyclic; in a Procedural Context, connections may be cyclic and more flexible.
Interpretation
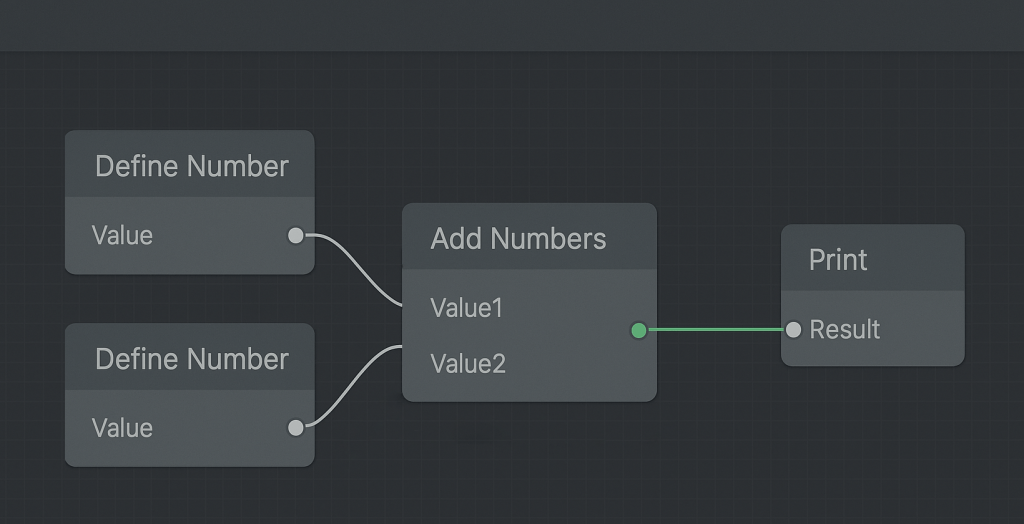
To illustrate the simplicity of the language, we can write a minimal interpreter in Python.
This interpreter handles an acyclic graph of nodes with Type, ID, attributes (all strings), and connections between attributes. Connections are represented directly as attribute values: if an attribute value starts with @, it refers to another node’s attribute (e.g., @Node1.Value).
For example:
DefineNumberoutputs a number in itsValueattribute.AddNumberstakes two numbers as inputs and produces aResult.Printconsumes theResultand prints it.
The interpreter maps node types to operators, executes them, and produces results.
# minimal_graph_interpreter.py
# A tiny, in-memory, non-cyclic node graph + interpreter.
# Nodes have: Type, ID, attrs (all strings). Connections are '@NodeID.Attr'.
from typing import Dict, Any, List, Callable, Optional, Tuple
Node = Dict[str, Any] # {"ID": str, "Type": str, "attrs": {str:str}, "state": {str:Any}}
def is_ref(value: Any) -> bool:
return isinstance(value, str) and value.startswith("@") and "." in value[1:]
def parse_ref(ref: str) -> Tuple[str, str]:
# "@NodeID.Attr" -> ("NodeID", "Attr")
target = ref[1:]
node_id, attr = target.split(".", 1)
return node_id, attr
def to_number(s: Any) -> Optional[float]:
if isinstance(s, (int, float)):
return float(s)
if not isinstance(s, str):
return None
try:
return float(int(s))
except ValueError:
try:
return float(s)
except ValueError:
return None
class Interpreter:
def __init__(self, nodes: List[Node]):
# normalize nodes and build index
self.nodes: List[Node] = []
self.by_id: Dict[str, Node] = {}
for n in nodes:
node = {"ID": n["ID"], "Type": n["Type"], "attrs": dict(n.get("attrs", {})), "state": {}}
self.nodes.append(node)
self.by_id[node["ID"]] = node
# map Type -> evaluator
self.ops: Dict[str, Callable[[Node], bool]] = {
"DefineNumber": self.op_define_number,
"AddNumbers": self.op_add_numbers,
"Print": self.op_print,
}
# ---- helpers ----
def get_attr_value(self, node_id: str, attr: str) -> Any:
"""Return the most 'evaluated' value for an attribute (state overrides attrs)."""
node = self.by_id.get(node_id)
if not node:
return None
if attr in node["state"]:
return node["state"][attr]
return node["attrs"].get(attr)
def resolve(self, raw: Any) -> Any:
"""Dereference '@Node.Attr' chains once (graph is acyclic so one hop is enough)."""
if is_ref(raw):
nid, a = parse_ref(raw)
return self.get_attr_value(nid, a)
return raw
def all_resolved(self, values: List[Any]) -> bool:
return all(not is_ref(v) and v is not None for v in values)
# ---- operators ----
def op_define_number(self, node: Node) -> bool:
# Input: attrs["Value"] (string number). Output: state["Value"] (numeric)
if "Value" in node["state"]:
return False # already done
raw = node["attrs"].get("Value")
val = self.resolve(raw)
num = to_number(val)
if num is None:
return False # can't parse yet
node["state"]["Value"] = num
return True
def op_add_numbers(self, node: Node) -> bool:
# Inputs: attrs["Value1"], attrs["Value2"] (can be @ refs). Output: state["Result"]
if "Result" in node["state"]:
return False
v1 = to_number(self.resolve(node["attrs"].get("Value1")))
v2 = to_number(self.resolve(node["attrs"].get("Value2")))
if v1 is None or v2 is None:
return False
node["state"]["Result"] = v1 + v2
return True
def op_print(self, node: Node) -> bool:
# Input: attrs["Result"] (@ ref). Side effect: print once. Also store state["Printed"]=True
if node["state"].get("Printed"):
return False
r = self.resolve(node["attrs"].get("Result"))
# Allow printing numbers or strings once the reference resolves
if r is None or is_ref(r):
return False
print(r)
node["state"]["Printed"] = True
return True
# ---- execution ----
def step(self) -> bool:
"""Try to make progress by evaluating any node whose inputs are ready."""
progressed = False
for node in self.nodes:
op = self.ops.get(node["Type"])
if not op:
# Unknown node type: ignore
continue
progressed = op(node) or progressed
return progressed
def run(self, max_iters: int = 100):
"""Iteratively evaluate until no changes (DAG assumed, so this stabilizes quickly)."""
for _ in range(max_iters):
if not self.step():
return
raise RuntimeError("Exceeded max iterations (graph might be cyclic or ill-formed).")
if __name__ == "__main__":
# --- Example in-memory graph ---
graph = [
{"ID": "Node1", "Type": "DefineNumber", "attrs": {"Value": "3"}},
{"ID": "Node2", "Type": "DefineNumber", "attrs": {"Value": "5"}},
{
"ID": "Adder",
"Type": "AddNumbers",
"attrs": {"Value1": "@Node1.Value", "Value2": "@Node2.Value"},
},
{"ID": "Printer", "Type": "Print", "attrs": {"Result": "@Adder.Result"}},
]
interp = Interpreter(graph)
interp.run() # Should print: 8.0
Running the example graph prints:
8.0Summary
The Divooka language demonstrates how a minimalist graph-based specification can serve as a foundation for both computation and orchestration.
Key takeaways:
- Node-Centric Abstraction: Everything is reduced to nodes with types, IDs, and attributes – uniform, extensible, and easy to interpret.
- Simple Reference Mechanism: The
@NodeID.Attrconvention provides a straightforward but powerful way to connect attributes. - Separation of Concerns: Distinguishing between dataflow (acyclic, deterministic) and procedural (control flow, cyclic) contexts allows Divooka to cover both declarative and imperative styles.
- Composable Operators: Even with just three operators (
DefineNumber,AddNumbers,Print), meaningful behaviors emerge. - Compact Interpreter Footprint: The entire interpreter is under 200 lines of Python, demonstrating the specification’s simplicity and rapid prototyping potential.
One might ask why not use traditional graph connections. The answer is simplicity: defining connections as local attribute references reduces structure while keeping graphs clean. In dataflow, inputs typically come from a single source, while in procedural contexts, outputs are unique but inputs may be shared, so we can just reverse the syntax – making this lightweight approach intuitive and efficient.
Reference
- Wiki (WIP): Divooka Language Specification